

It’s so easy to find yourself bogged down when trying to figure out the meaning of the indexing reasons signaled by Google Search Console.
In the spirit of truth, not only do I find it tricky to recall the names of problematic indexing reasons, but sometimes can’t catch the gist at their root either.
What do those common indexing flags mean and how should I behave in case I encountered them?
The guide provided me with a neat overview of potential bottlenecks in crawling and indexing performance. Actually, it helped me better discern SEO warnings from real issues.
It also inspired me to transpose the concepts into storytelling to better digest their rustiness. And, hopefully, producing helpful content.
In this post, I will briefly cover the crawling and indexing process at Google and eventually reveal the most common indexing issues raised from the Page Indexing report on Google Search Console.
How Crawling and Indexing Works
Following a search query prompt, Google returns search results depending on crawling and indexing performance
| Crawling | Google downloads text, images, and videos from pages it found on the internet with automated programs called crawlers. |
| Indexing | Google analyzes the text, images, and video files on the page, and stores the information in the Google index, which is a large database |
Anyway, the Official Documentation fails to address a crucial intermediate process. As we’ll see later in the article, the Rendering process is the man-in-the-middle in charge of parsing HTML and CSS elements of a page to ultimately deliver an updated version to the latest user interaction.
Crawling
In the first stage of web crawling, Google discovers pages on the web by following links. These pages may be popular hubs, such as category pages or blog posts.

Googlebot would explore the website like a tourist visiting a new city. However, it may encounter closed roads or narrow paths that discourage further exploration. As a result, the web crawler may take breaks before continuing its search.
Who is Googlebot?
Googlebot (crawler or web spider) is the algorithmic program that fetches resources along its way in a bid to determine which sites are worth following, how often, and for how many pages. Googlebot doesn’t crawl all the pages he discovered. Some pages may be disallowed for crawling by the site owner, other pages may not be accessed without logging in to the site, and other pages may be duplicates of previously crawled pages.
Actually, Googlebot’s discovery capabilities are extremely limited despite trying its best to resemble a user.

💡Tip💡
If your content requires Google to click, scroll, or perform any other action in order for it to get loaded onto the page, you shouldn’t be surprised if it doesn’t get indexed. Rather, chase down for JavaScript or other layout styling making up the GUI of your site.
Rendering
Speaking of Googlebot and its limitations leads us to introduce a bridge between the Crawling and the final Indexing stage. This connection looks a lot like a Tibetan bridge as JavaScript could intervene and hamper the passage to the indexing stage.
During the rendering phase, Googlebot fetches the structure and colors of a web page by merging the parsed HTML (DOM) and CSS (CSSOM) and running any JavaScript.
This is important because JavaScript can affect the content of a page. When a user requests a web page, the browser communicates with the server to request and receive the page, along with status codes and other HTTP responses.
Here is at a glance what happens during the conversations between the Browser and the Server
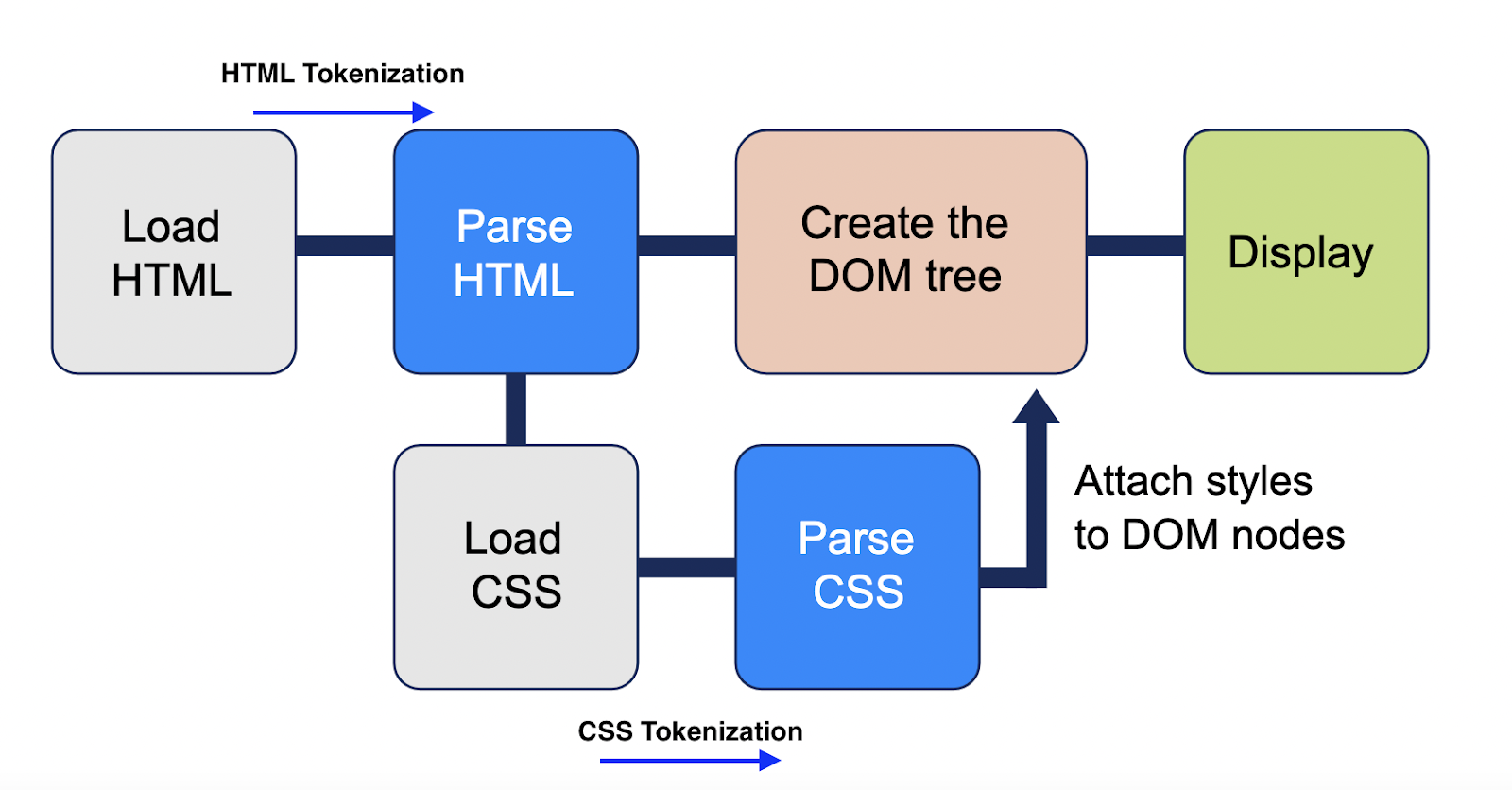
The HTML tokenization is a process where bits of the HTML are split into several tokens for better comprehension while they get parsed. When the HTML gets parsed, a DOM is produced.
💡 The DOM is the result of the HTML parsing after tokenization and represents an up-to-date treemap of a website with the latest JavaScript addition, following a user interaction.
CSS tokenization is a process where bits of CSS is split into several tokens for better comprehension while they get parsed. When the CSS gets parsed, a CSS Object Model is generated.
💡 The CSSOM is the result of the CSS parsing after tokenization and contributes to providing layout style, such as colours, to the website.
To put it simpler:
Rendering = DOM + CSSOM
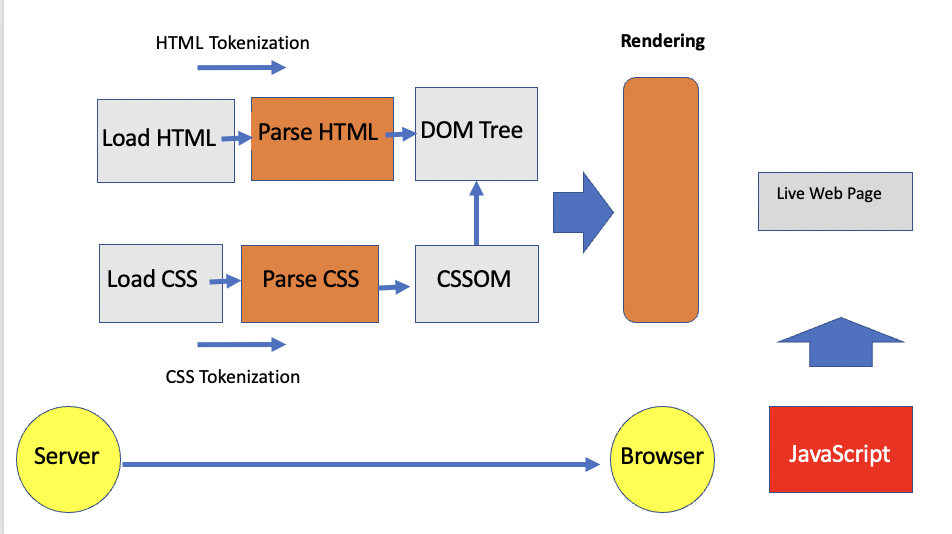
Hence, once the browser shows the rendered version of a website JavaScript might intervene to allow users to interact with the website. This may cause a few tweaks to the DOM due to the addition or removal of elements from the DOM tree.
You can assume that crawling patterns may require different skillset and become time-consuming depending on the type of website that Googlebot comes across.
As recent analyses proved, If a website relies on JavaScript for user interaction, web crawlers will spend something like 9 times more to crawl the website.
As rendering takes additional computing resources, JavaScript-reliant pages will be put on hold also in the rendering queue other than the crawl queue

This likely translates into a waste of the so-called crawl budget.
💡BONUS
Crawl budget tends to be such a biased metric in SEO. Why don’t replace it with a more accurate metric instead? Learn how to measure crawl efficacy in Python with this short tutorial
Indexing
If your page successfully passes on to the next stage, you can sit back and relax.
Maybe.
Once a crawled page joins the indexing stage, Google runs an in-depth analysis of your page’s textual content and meta tags, such as <title links> and <meta descriptions>
During the indexing process, Google determines if a page is a duplicate or canonical. The search engine runs several cluster analysis tasks to group up similar pages and thereby pick up the most representative.
Factors that come into play are:
- Language of the page
- The country where the content is local to
- The usability of the page

But also:
- E-A-T (Expertise, Authority and Trustworthiness) of the entire domain
- Topical Relevance of entities presented on a page compared to the rest of the sample. This assessment may result from a range of tasks relying on supervised machine learning models such as Topic Modeling.
- Links, in terms of quantity and the quality of the referring domains from where they come from.
- The quality of the content. In case it appears as low quality, thin content or just fluffy content, Google may decide not to index it and this might be flagged as an indexing issue
- Obstructive Robots meta directives that disallow indexing.
- A hard-to-render GUI of the website. This is especially true for sites relying heavily on JavaScript frameworks (SPA).
💡BONUS
You could use keyword density to learn more about topical coverage just by using a Python script
Now that we know a lot more about how Google Search works, let’s dive into the common indexing issues that your Search Console property might raise.
👇🏻 Further Resources
How Search Engines Work by Moz
How Search Engines Crawl and Index by the Search Engine Journal
9 Common Google Search Indexing Issues
After rolling out a more simplified Coverage Report, Google Search Console started disclosing an overview of problematic indexing from the “Pages” section.
Here are the most common indexing issues that may appear:
- Server error (5xx)
- Indexed URL blocked by Robots.txt
- Soft 404
- Not found (404)
- Blocked due to access forbidden (403)
- Alternate page with proper canonical tag
- Duplicate without user-selected canonical
- Duplicate, Google chose different canonical than user
- Page with redirect
Let’s delve into them.
Server error (5xx)
This is the case where your server returned a 500-level error when the page was requested.
This one often tends to resonate with issues more than warnings
| Warning | Issue |
| ❌ | ✅ |
Although Google’s crawlers are programmed to run at an acceptable pace to avoid crawling the site too fast, sometimes the Page Indexing report could utter an HTTP server error response 5xxx.
That means that Googlebot couldn’t access your URL, the request timed out, or your site was busy. As a result, Googlebot was forced to abandon the request.
💡How To Solve?💡
- Reduce excessive page loading for dynamic page requests.
- Make sure your site’s hosting server is not down, overloaded, or misconfigured.
- Check that you are not inadvertently blocking Google.
- Control search engine site crawling and indexing wisely.
Find out more on Google Documentation
Indexed URL blocked by Robots.TXT
While there are many reasons for blocking pages, sometimes Google may decide to index a discovered page, although it was unable to crawl and understand its content.
During the English Google SEO office hours from October 2022, Google’s John Muller claimed that having plenty of “Indexed, though blocked by robots.txt” pages is not the end of the world as these pages would show up only behind thorough research.
In plain English, if your pages are indexed but blocked by robots.txt, you shouldn’t freak out as the average user wouldn’t normally stumble across them when performing a Google search
When internal or external links point to a blocked page, it may still get indexed by Google. This can negatively impact SEO, leading to poor search appearance and unwanted traffic.
This flag should be treated as a potential Warning.
| Warning | Issue |
| ✅ | ❌ |
💡How To Solve?💡
To make sure a page is eligible for getting indexed, remove the robots.txt block and use a ‘noindex’ directive.
Soft 404
The requested page returns some sort of user-friendly “not found” message without a corresponding 404 response code.
This one used to be a noble page that has recently seen a gradual downturn in its reputation.
Depending on the size of the website and the frequency of this event occurs, we can raise some assumptions about enshrining this flag as a warning or an issue.
| Warning | Issue |
| 👀 | 👀 |
💡How To Solve?💡
- Google recommends returning a 404 with a custom landing page providing the right directions to users so they can continue browsing your website as seamlessly as possible.
- Alternatively, Google suggest adding more information to the page so you let the search engines know that the page shouldn’t be treated as a soft 404.
Not found (404)
If your request to access a webpage is denied, this means Google might have discovered the URL as a link from another site, or possibly the page existed before and was deleted. Googlebot will probably come back and crawl this URL for a little while.
Depending on the volume of traffic and the links hosted on a 404 page, you should decide whether to redirect it to the “closest” page in terms of semantic proximity or, conversely, apply a 410 to order a permanent removal.
Backing our assumptions with the above, you may probably classify this event more as a Warning
| Warning | Issue |
| ✅ | ❌ |
💡How You May Try to Solve?💡
If you want to delete a page returning 404, you should seriously consider using a 410 to reduce the crawling frequency of that page and accelerate the demotion process, as this recent study has confirmed.
Blocked due to access forbidden (403)
What happens here is something you definitely want to avoid.
Googlebot is not able to access a portion of your website because it doesn’t have the keys to enter. This is an important bill as it is very likely to curb crawling and indexing performance. And the reason for that is Googlebot likely to grow sick and tired of forcing a door he can’t open, thereby storming off and never coming back.
This usually happens when a site still resides in a staging environment and requires credentials to access the back-end. If that is the case, though, once your site goes live you need to make sure it is fully crawlable. This means you should allow crawling directives within your robots.txt and amend the meta tag robots as Index,follow.
Unsolicited 403 errors will vanish on their own if you did everything right.
If this is not the case, you should make sure you’re not locking traffic-making or revenue-magnetic pages behind sign-in pages that require credentials.
| Warning | Issue |
| ❌ | ✅ |
💡How To Solve?💡
If you do want Googlebot to crawl this page, you should either admitting non-signed-in users or explicitly allowlist googlebot.
Alternate page with proper canonical tag
The easiest way to explain this indexing issue is to use a metaphor.
Googlebot trawled through a real estate catalog with plenty of houses to let. After picking up a bunch of offerings, it walked down the street to pay a visit to a surveyed property. Once it got to its destination, despite taking it a few miles, it recognized this house is exactly the outstanding choice he browsed earlier from the catalog.
In other words, in such a situation, a specific page is a duplicate of another that Google recognizes as canonical. This page correctly points to the canonical page, which is indexed, so there is nothing for you to do.
This flag could be classified as a warning since it deals with potential room for duplicate content issues. This might be due to the fact that your site doesn’t abound with self-referencing URLs, but they rather outsource the canonical to a different page.
| Warning | Issue |
| ✅ | ❌ |
💡Tip💡
Bear in mind that sometimes there’s nothing wrong in avoid self-referencing URLs and outsource the canonical attribute.
For example
| ❌ Wrong | Self-referencing filters (i.e color, size) from product pages |
| ✅ Right | Self-referencing a product page to set it apart from its category root |
Duplicate without user-selected canonical
This status indicates that Google has not indexed a specific page due to it being a copy of another page, and no canonical page has been specified through the use of the canonical tag.
Duplicate without user-selected canonical is caused by:
- Content duplication: when the body of a page changes regardless of the footer and the header. This may be due to technical issues with the CMS or server but it can also occur when you don’t put enough effort into making all of your pages unique.
- Incorrect canonical tag usage: the canonical tag was not used on the set of URLs. Hence, Google will likely select automatically one of the pages to index regardless of your preference
| Warning | Issue |
| ❌ | ✅ |
💡How To Solve?💡
To help Google determine which version of the page to index, it’s recommended to utilize canonical tags, XML sitemaps, and redirects.
Duplicate, Google chose different canonical than user
“Duplicate, Google chose different canonical than user” means you have specified a canonical rule on a list of URLs but Google has chosen a different one.
If a page is marked as canonical but Google thinks another URL makes a better match, then canonical will be applied to this variation.
| Warning | Issue |
| ✅ | ❌ |
There may be a ton of reasons for Google to choose a different canonical
On Twitter, Kristina Azarenko addressed the topic with a quick thread. She reckoned there are 5 key reasons boiling down to duplicate content issues.
It’s one of the most frustrating things in technical SEO…
— Kristina Azarenko (techseo.pro) 🔥 (@azarchick) October 12, 2022
You set up a canonical tag…
But Google chooses something else.
Here are 5 reasons why it might happen.
A 🧵
But what are the criteria Google follows in deeming a page canonical?
According to one of the latest takes from the Search With Candour podcast, when search engines pick a given URL as canonical, there seems to be a slight preference for short URLs
Whether this has never been confirmed by Google, we can confirm the prominence of internal links on a page is still the major factor that prompts search engines to retain a URL as the canonical version.
Although short URLs tend to work better from both a user experience and a search perspective, bear in mind that it’s not worth the risk to trim a URL structure that is crunching organic traffic.
💡How To Solve?💡
You can inspect the URL on Google Search Console to see what’s the Google-selected canonical URL. Then, you should consider whether the chosen canonical is appropriate for your business.
- If the new canonical that Googlebot picked up truthfully legitimates your business, then you’d better apply the new rel=canonical to that page.
- If the new canonical fails to identify a rightful version of your page, you’d better let Googlebot know that it’s getting it wrong and resubmit the old rel=canonical.
Page with redirect
If you’ve ever come across the term “Page with redirect” in your SEO, you may be wondering what it means and if it’s an issue.
This status means that some of your pages aren’t indexed because users and crawlers are being redirected to other URLs. When this happens, Google will index the target URL instead, and the original URL that’s been redirected won’t be crawled or indexed.
The main causes pulling this status in Search Console are:
– Messy redirects originated by mistake
– Faulty temporary redirects that Google considers to be permanent after some time.
Anyway, “Page with redirect” are most often not an issue since it’s likely In fact, it’s likely those redirects will turn into 2xx pages at some point.
| Warning | Issue |
| ✅ | ❌ |
💡BONUS
To ensure search engines acknowledge the change, it’s recommended to keep your redirects in place for at least 12 months.
Final Thoughts
Nobody knows how the machine learning models at the search engine kernel trigger Googlebot’s decisions in rating your pages.
This is actually the reason why there are no straight answers in SEO, meaning you need to find out what works best for your site to rank. Likewise, the problematic indexing bills flagged from the Page Indexing report should be evaluated with an eye peeled for your website’s specifics.
However, clearing a bit of nuance from the Page Indexing report can help you distinguish issues from warnings and ultimately prioritize your next SEO moves.
FAQ
-
What is Crawling?
Crawling is one of the ordinary tasks processed by search engines when discovering your website’s pages. It’s important to note that search engines will only use links and avoid actions such as clicks or scrolling to move from one page to another.
-
What is Rendering?
Rendering is an intermediate indexing stage before indexing that mainly regards JavaScript-based interfaces. During this phase, search engines work toward reading and parsing such resources so they can be successfully delivered to the browser once users make a request for a webpage.
In other words, rendering requires search engines to successfully parse a website’s JavaScript dependency
-
What is Indexing?
Indexing is the ultimate stage of indexation where search engines store the successfully parse web page’s content in the browser’s index. Once this is achieved, the content will be available to access for users.
-
What is the Difference Between Crawling and Indexing?
Crawling is the discovery process of one’s page content from search engines.
Indexing is the ultimate process aimed to successfully store the page’s content in the browser’s index and make it available to users. -
What are the most common Indexing Issues?
On the Index Coverage Report in Google Search Console, there may appear so many indexing warnings or issues posing a threat to your organic search performance.
Some of the most common indexing reasons are:– Server error(5xx)
– Indexed URL blocked by Robots.txt
– Soft 404
– Not found (404)
– Blocked due to access forbidden (403)
– Alternate page with proper canonical tag
– Duplicate without user-selected canonical
– Duplicate, Google chose different canonical than user
– Page with redirect -
How do I check for Indexing Issues?
You can check on indexing warnings/issues by keeping monitored the Index Coverage Report in Google Search Console.
Checks should be carried out on a weekly basis, albeit this will vary on the website’s size -
How do I know if Google is indexing my site?
To learn about your content indexation, you should consult the URL inspection tool from the Google Search Console property.
To sense-check indexation, though, it’s recommended to play around with a simple site:search
-
How do I get Google to index my site?
There’s no magic formula to ensure your web pages will be indexed on Google.
Indexation is not provided as an untouchable right to webmasters, rather it’s a successful achievement.
There are two main recommendations to aim for successful indexation:
– write helpful content that aims to satisfy a specific search intent without wandering off from the main topic lane.
– build a meaningful internal linking structure that helps users and search engines navigate through related entities on your site
– build a safety net of external connections by linking to the highest authoritative sources your page content may refer to.

Simone De Palma
Technical SEO Executive